Types of scans in API Scan
You can use API Scan to run different types of scans that focus on different aspects of your API implementation. In all scans, the underlying scan engine is the same, but the scan configuration that the engine uses includes different instructions on what kind of requests to generate for the scan.
Different scan types are only available only when using Scan v2 engine. Scan v1 engine can only run conformance scan.
API Scan can run the following types of scans:
- Conformance scan: A design-time scan to ensure that you do not inadvertently introduce vulnerabilities and your code and API implementation matches the documented contract in your API definition. Both OpenAPI definitions and GraphQL APIs are supported.
- Drift scan: A lightweight scan on deployed and operational APIs to ensure they continue to work the expected way. Currently, only OpenAPI definitions are supported.
When viewing the list of scan configurations, each configuration shows a label indicating what type of scan can be run with it.
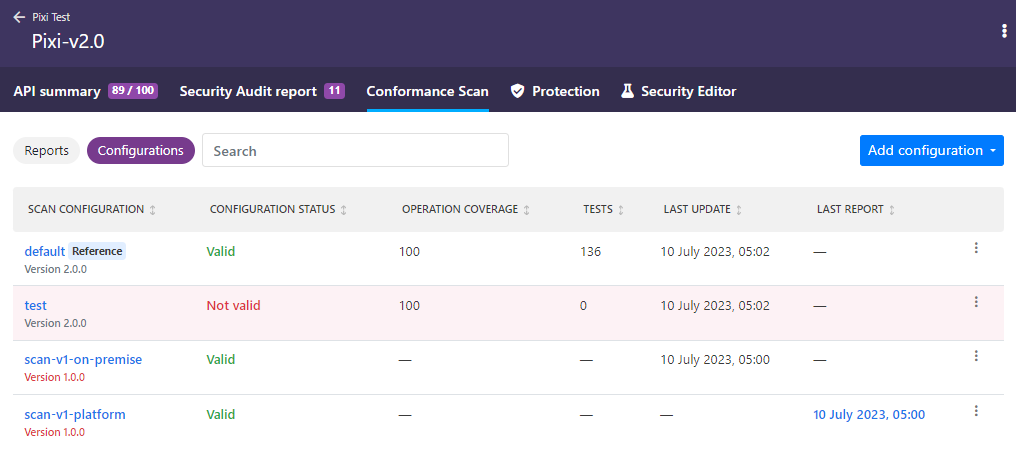
By default, each scan configuration is only of one type and runs only one type of scan. However, as you edit and enhance a scan configuration, it may combine different scan types into the same configuration. In this case, you can assign additional scan types for your configuration as needed.
Remember that running invasive scans that can modify data against live APIs in production that you do not yourself own and control is against our terms and conditions and thus not allowed. If you edit your drift scan configuration to include fuzzing on operations that modify data, such as POST and DELETE, you must only run it on your own APIs.
Conformance scan
Conformance scan is the traditional scan that API Scan runs to check how your API implementation conforms to the contract set in the API definition of the API, to find out if there are any mismatches between the API definition describing your API and what it actually does. If API Scan finds any discrepancies, it reports the issues clearly so that you can fix them. This helps avoid introducing discrepancies and vulnerabilities when designing and developing your API implementation in the first place.
Fuzzing in conformance scan
The key function in conformance scan is fuzzing. Once API Scan has run the happy path tests to get a baseline for what a success for a particular API operation looks like, it is ready to test if the API implementation correctly catches and handles malformed or erroneous requests. Conformance tests are based on the happy path requests and designed to uncover issues in the error handling of your API implementation and where it does not conform to what the API definition of the API declares.
Fuzzing means that each test marked for fuzzing includes an intentionally tweaked element (header, body, parameters, HTTP method) so that the request no longer matches what the API expects. The tweaks that API Scan does in the conformance tests fall into three categories:
- Omit: API Scan omits an element that the scanned API definition requires from the request
- Add: API Scan adds an extra element that is not included the scanned API definition into the request
- Fuzz: API Scan changes an element of the request so that it no longer matches what is defined in the scanned API definition (for example, using a value that does not match the schema constraints)
The implementation of the API should catch this and respond accordingly.
Response validation in conformance scan
API Scan tests how the API implementation handles, for example, requests to operations not defined in the API definition at all, or misconfigured requests to existing operations. How the API responds to the crafted test requests in the scan determines whether or not it conforms to the contract it sets out in its API definition. To catch issues, API Scan validates the response from the API and considers, for example, the following:
- Is the provided HTTP status code defined in the
responseobject in the API definition? - Are all headers in the response defined in the
responseobject in the API definition and do they match the definedschema? Are all required headers present in the response? - Is the returned response body too big?
- Should the response even have a body (method
HEADor returned status codeHTTP 204)? - Does the
Content-Typeof the returned response match the types defined in the content map in the API definition, and does it match the definedschema?
Response validation is done in two parts:
- Response code: Did error handling work? Did the received HTTP status code in the API response match what API Scan expected or not? Or in the worse case, did the intentionally malformed request not raise an error at all?
- Contract conformity: Did the received response match what is defined in the API definition of the API?
From security risk perspective, incorrect error handling poses a bigger risk for the API implementation than response content, and therefore API Scan focuses on it first.
- For requests to non-existing operations, API Scan expects the API to respond with
HTTP 405 Method not allowed. Any other response is considered to be wrong. - For misconfigured requests to existing operations:
- The returned HTTP status code must be equal to or greater than
HTTP 400to indicate an error. - The returned HTTP status code (or a
defaultresponse) must be defined in the API definition of the API.
- The returned HTTP status code must be equal to or greater than
Based on this, API Scan splits the received response codes into three classes:
- Incorrect: The API did not raise an error, but responded with a success to a malformed request. This means that the API implementation does not catch and handle the error at all, indicating serious problems.
- Unexpected: The received response code does not match what API Scan expected for the test request, but the API implementation still raised an error, if not the correct one. This means that there are some problems in the error handling in API implementation, but at least the issue is caught.
- Expected: The received response code matches what API Scan expected for the intentionally malformed request, and the API implementation raised the error correctly. This means that the API behavior is good.
However, even if response codes match what API Scan expects, it does not mean all is well. API Scan could also uncover discrepancies between the API contract set out in the API definition and the backend API implementation:
- The returned response body must match what is defined in the API definition for the returned HTTP status code.
- The returned response headers must match what is defined in the API definition (if response headers are defined).
Based on analyzing the response bodies and headers, the received responses are flagged either conformant or not conformant in respect to the API definition.
By default, API Scan does not follow redirects (HTTP 3XX) in API responses to analyze the
final response, but instead analyzes the received redirect. Depending on your API, this could result in conformance failure if the response definition in you API is the expected final response that the redirects would lead to. You can change this behavior in scan settings, if needed, but we do not recommend it as it may prevent the scan from completing: the final response from a redirect could often be in an unsuitable format, resulting in error. By not following redirects, API Scan can complete and successfully evaluate the main concern: is the error handling of your API implementation working as it should.
Conformance scan report
Running a conformance scan produces a report that focuses on how well your API implementation matches the contract set out in the API definition of your API.
For Scan V1 engine, you can have a total two reports available for a single API: one from the latest scan run in 42Crunch Platform another one from the latest scan run on premises.
In the scan report, the tests and their findings are listed by path and operation, and one operation can have multiple tests run against it, in which case it lists the results for all of them. Above the list of found issues, you have "Critical to Success" filter bar that you can use to home in on the scan results:
- OWASP vulnerabilities: Which OWASP API Security Top 10 vulnerabilities API Scan found in your API implementation.
- Operations not tested: Which operations could not be tested in the scan and why.
- Test results: How the received API responses were classified in response validation. The results are grouped in the order of severity, starting with the most critical issues on the left. As you address the issues, they move to the right towards the other end of the scale where everything is good.
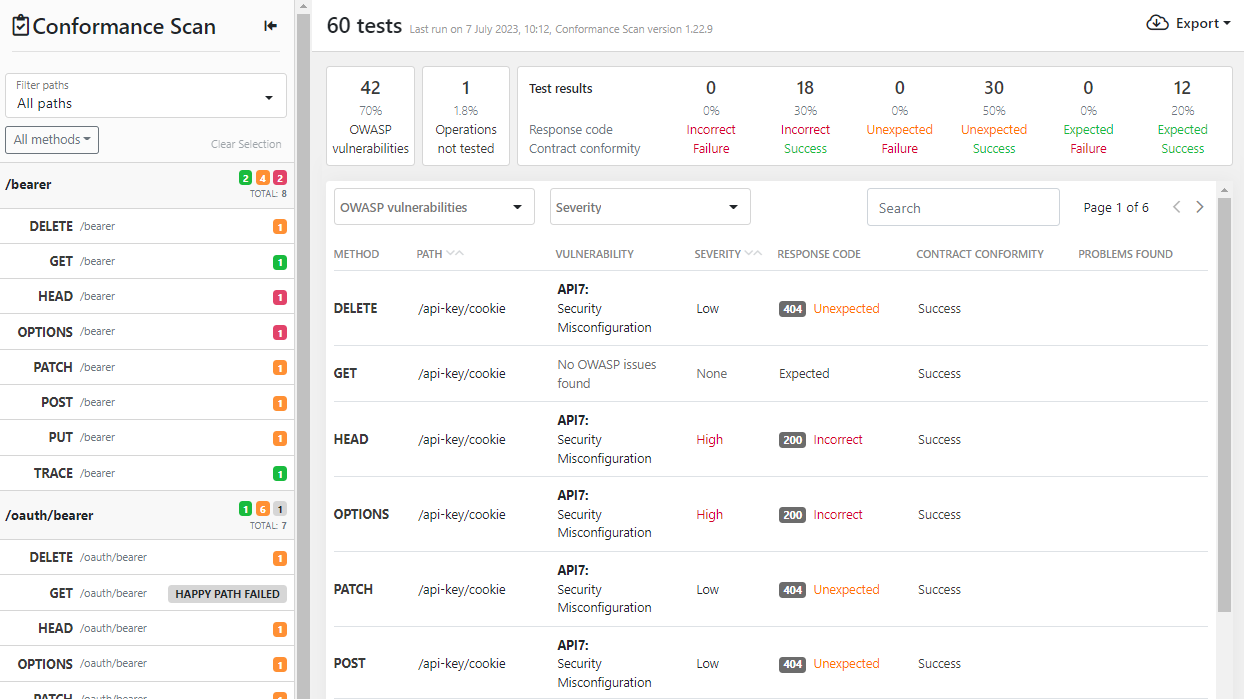
The filter bar also shows the distribution (in percentage) of the test results between different result classes.
You can click on the filters to view only the results you are interested in. These filters are not cumulative, meaning that clicking on one changes the listing completely, it does not add more results to the existing view. However, within these main filters, you can further refine the current result list using the additional dropdown filters.
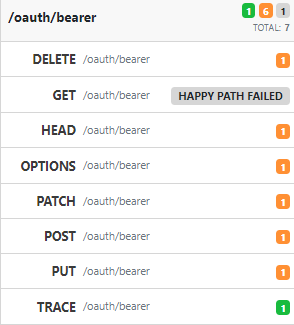
The filter sidebar on the left lets you filter the results by path, and also shows how many issues were found in each path, as well as which operations the scan had to skip, for example, because the happy path test failed.
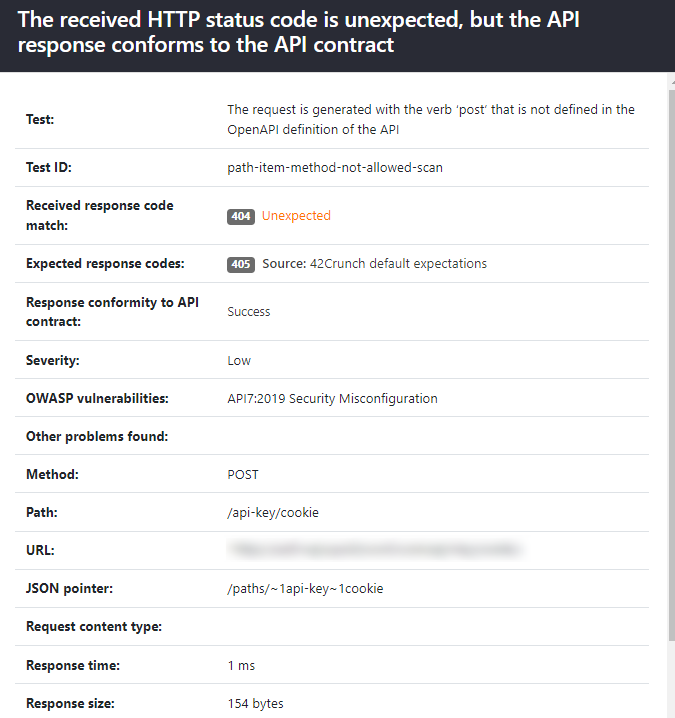
Clicking an issue in the result list provides further details on it, such as the description and ID of the test that the scan performed, the URL the scan called, the response time of the API, and the size and content type of the response. The issue details also show which response codes API Scan expected to receive as well as where that expectation comes from.
To make it easier to reproduce the results, reports also provide the cURL requests the scan used to detect each issue.
For Scan v2 engine, each scan configuration you have retains the latest report when the configuration was used to run API Scan. The list of reports you can view can therefore be much longer than for Scan v1 engine.
The summary of the report provides you quick at-a-glance summary that shows some main statistics from the scan, for example:
- How many tests were executed and how many and how severe issues were found?
- Which OWASP API Security Top 10 vulnerabilities API Scan found in your API implementation?
- Did the API pass or fail the SQG?
- How well do the API responses conform to the API contract?
- How good coverage did the selected scan configuration provided for your API?
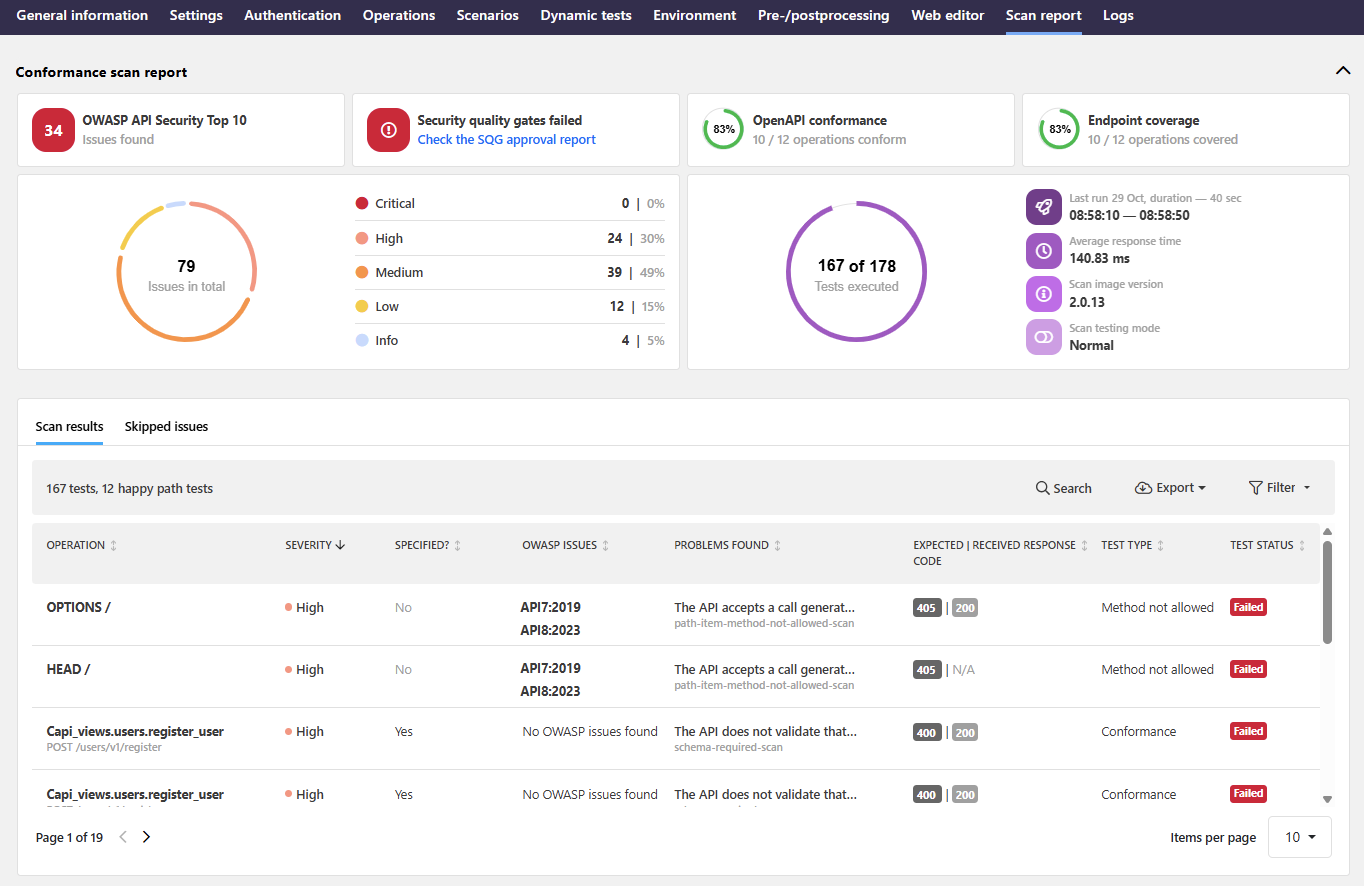
All found issues are listed below the summary and you can home in on what is shown and in which order by using the provided filters to view only the results you are interested in.
Clicking an issue in the result list provides further details on it, such as what the scan did (including the description and ID of the run test), did the received response match what the scan expected, and where in your API the issue occurred. The request and response tabs provide more details on the request that the scan sent as well as the response it received.
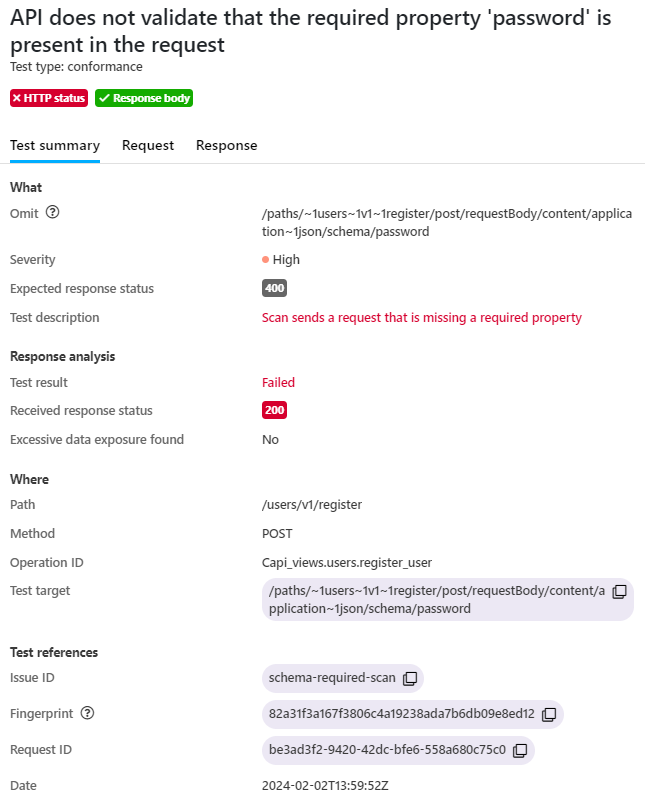
Each issue includes a unique fingerprint (identifier). This fingerprint remains the same in subsequent scans until the issue has been fixed, meaning that it can be used to track fixing of the issues.
For Scan v2 engine, each scan configuration you have retains the latest report when the configuration was used to run API Scan.
The summary of the report provides you quick at-a-glance summary that shows some main statistics from the scan, for example:
- How many tests were executed and how many and how severe issues were found?
- Which OWASP API Security Top 10 vulnerabilities API Scan found in your API implementation?
- Did the API pass or fail the SQG?
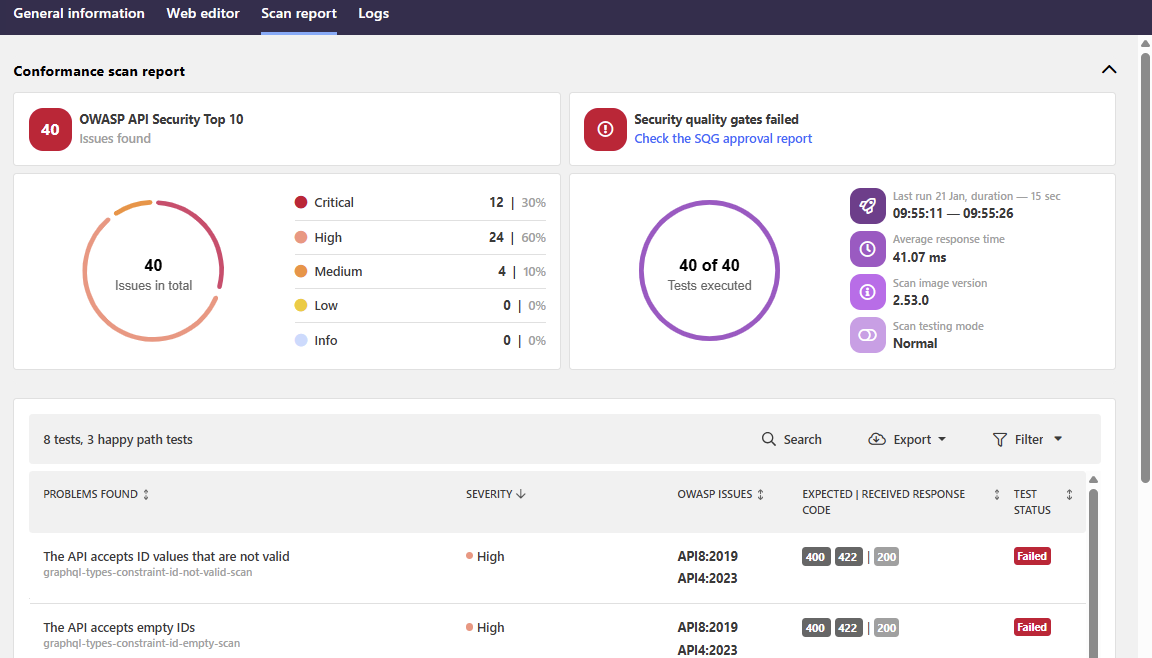
All found issues are listed below the summary and you can home in on what is shown and in which order by using the provided filters to view only the results you are interested in.
Clicking an issue in the result list provides further details on it, such as what the scan did (including the description and test ID of the run test), did the received response match what the scan expected, and where in your API the issue occurred. The request and response tabs provide more details on the request that the scan sent as well as the response it received.
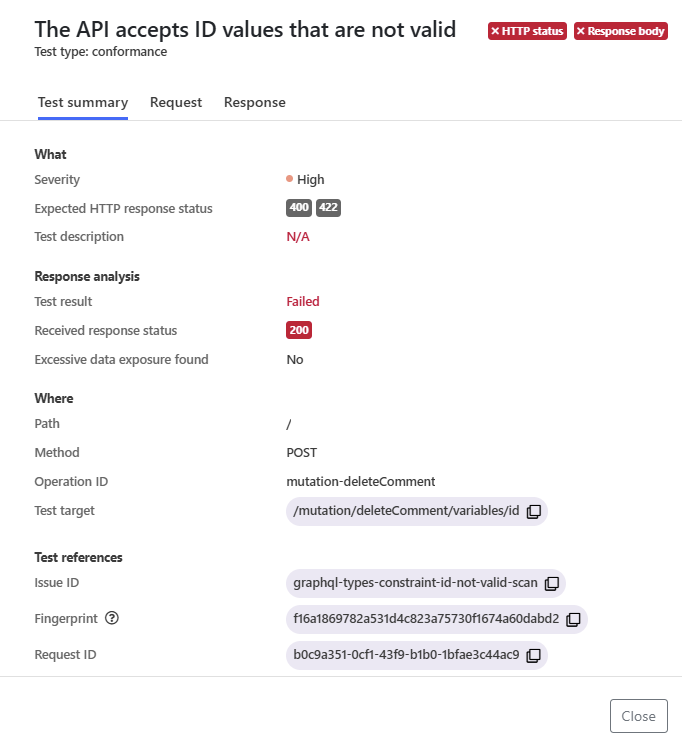
Each issue includes a unique fingerprint (identifier). This fingerprint remains the same in subsequent scans until the issue has been fixed, meaning that it can be used to track fixing of the issues.
Drift scan
Although it is only natural for APIs to change as new business needs arise and further iterations are done, if changes are not managed properly, it can lead to problems. API drift happens when APIs over time start deviating from their initial documented API contract when additional development happens in an uncontrolled manner, for whatever reason.
API drift can lead to high technical debt, with constant fixing of bugs, as well as dissatisfied and confused API consumers who cannot figure out how to use your API. API drift is not a mere documentation issue: APIs no longer working the way they were supposed to can also cause them no longer to align with the core business needs, or operational infrastructure or setup, and surprise breaking changes can break backward compatibility. It can also be outright dangerous, allowing for attacks through malicious input or unauthorized access to potentially sensitive data, possibly extending even beyond your organization if your API integrates with 3rd party services.
This is where a drift scan comes in. Drift scan is a light-weight, non-invasive scan that API Scan runs to detect API drift and ensure that your operational application infrastructure does not change without notice behind your back. This allows you to make sure that the documented API contract continues to evolve hand-in-hand with the overall API implementation.
Today, APIs are rarely self-contained. Responses are often shaped by downstream dependencies across a complex supply chain of external services, each introducing potential vulnerabilities or even malicious content. This is why drift scan also extends to 3rd party APIs your APIs integrate with, so that you have better visibility into your API dependencies and supply chain to detect unscheduled or unexpected changes that may cause breaking changes for your own APIs and applications. Drift scan is based on a subset of conformance scan, but because the scan involves 3rd party APIs, there is a crucial difference: a drift scan only sends GET requests and thus does not do any real fuzzing, to avoid causing issues to operational systems that you do not own or control.
Drift scan should be considered as a monitoring tool for your existing live API deployments, not a qualitative design-time tool. Drift scan is not supported in IDE or for GraphQL APIs.
Drift scan status and report
Drift scan checks do all API endpoints still work as documented in the API contract describing them or has something changed. Because drift scan is meant as a monitoring tool, it is geared more towards creating automated alerts on downstream services, for example, based on scan logs or scripting. However, drift scan status and report are naturally also available on the platform UI.
With production environment, time is of essence for discovering potential problems. Therefore the status of drift scan is surfaced already on API collection level: if API drift is detected and an API fails the drift scan, the API collection where that API is located is clearly indicated so that you know there is something there that needs your immediate attention.
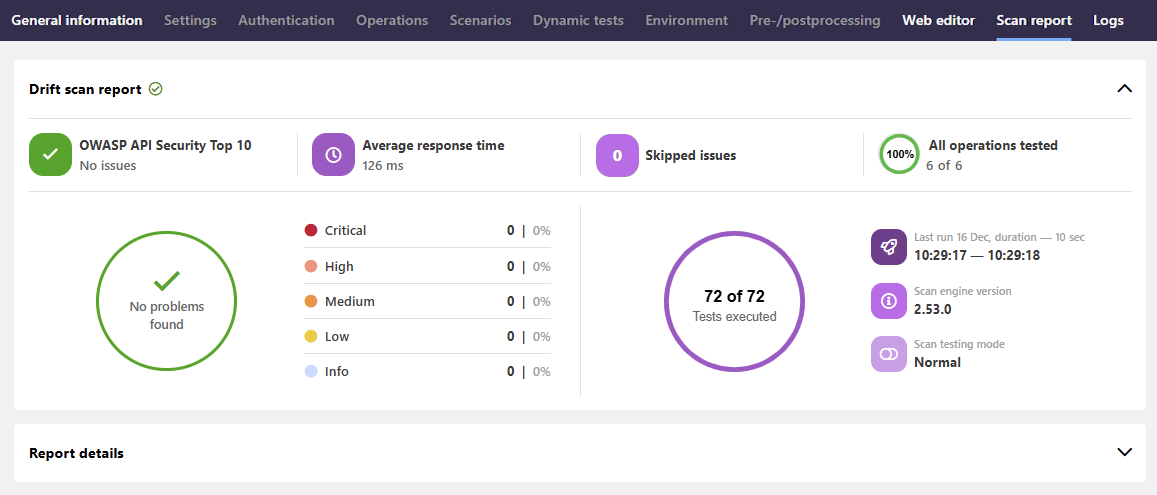
As drift scan is meant for monitoring your production APIs, normally you would expect everything to be good, with no API drift detected. In this case the drift scan report shows you the summary of some basics statistics, such how many tests were executed and the average response times from the scanned APIs. To drill into further details, for example, on happy path requests, you can expand the report details.
If the drift scan detects API drift, this is clearly indicated so that you know you need to take action. You still get the summary of statistics at the top, but now the report details are automatically expanded so that you can dive right in. Because drift scan is meant for monitoring live production, any failed happy paths requests are considered as a sign of potential API drift that requires investigation.
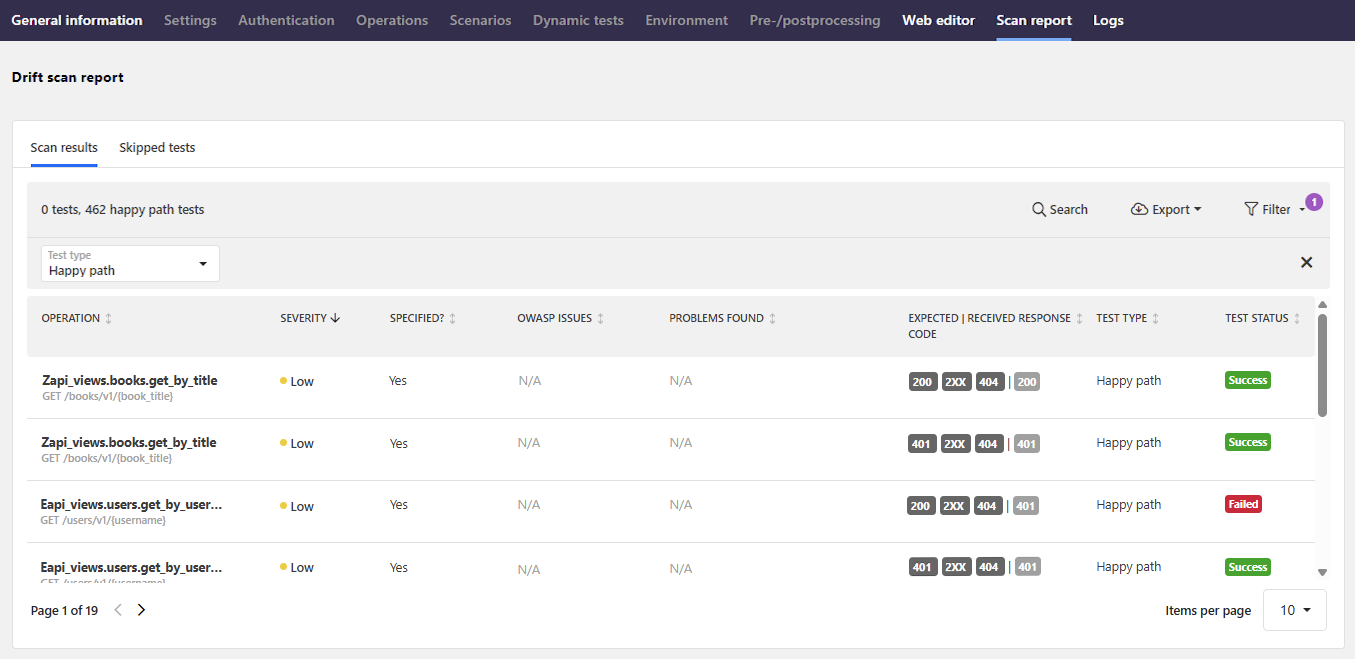
The report details are split into separate tabs to make it quicker to home in on the details you want:
- Scan results: The familiar list of problems that the scan found, like in conformance scan.
- Happy path tests: The details of all happy path tests that the scan run. Just like in a conformance scan, the happy path requests are build directly from the API contract documented in the API definition and the expected response codes are the same as in conformance scan. However, in addition to that, a drift scan intentionally sends out another happy path request without the required authentication information and specifically expects to receive
HTTP 401. This allows monitoring that the authentication measures on endpoints also continue to protect the API implementation from unauthorized access. - Errors: The list of errors (if any) that the scan encountered during execution, such as problems with connectivity or timeout, or scan flow errors.
- Skipped tests: Any tests that were skipped during the scan.
Clicking an issue in the result list provides further details on it, such as did the received response match what the scan expected, and where the issue occurred. The request and response tabs provide more details on the request that the scan sent as well as the response it received. In contrast to conformance scan report, by default drift scan only tests GET requests, so other operations, even if present in the API definition, are not tested in a scan.
We will continue to adapt and improve the drift scan report in future releases.
What is...
How to...
Learn more...