API Scan
API Scan is a dynamic runtime analysis that runs checks on your live API implementation to discover issues and vulnerabilities in how your API and the backend services behind it behave.
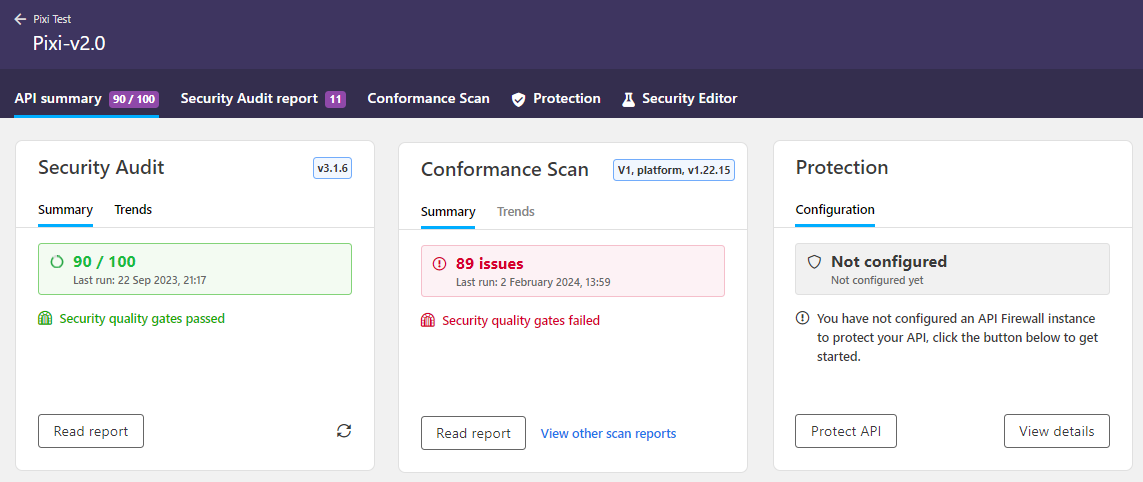
The scan generates real traffic to the selected API endpoint and could incur costs depending on your setup.
For best results, make sure that your API definition is valid and well-formatted before you scan it. The API must be deployed so that the API endpoint is live, and the backend server your API uses must be accessible to API Scan. Otherwise the API cannot be scanned.
API Scan can have potential side effects: APIs can throw exceptions, fail, and data can be affected. As per our terms and conditions, you must only run invasive scans, such as conformance scan and fuzzing requests, against APIs that you own, and only against non-production systems and non-production data! Do not run other scan types except the non-invasive drift scan in production environment!
Scan v1 and Scan v2 engines
We have introduced a new version of API Scan engine, referred to as Scan v2. For backward compatibility and to avoid the adoption of the new version disrupting your day-to-day work, we have retained the previous version, Scan v1.
Both versions of the API Scan engine share the same core features and operation, but the new Scan v2 engine offers additional features and more flexibility, such as:
- Multiple scan configurations for a single API that you can edit and iterate on
- New scan types
- New scan settings
- Optimizing scan report size, for example, by skipping curl requests in the report
- Validating just the response code, not the response, for happy path tests
- Scan scenarios
- Only fields defined as
requiredare validated in happy path tests - Automated credential generation
- Improved scan report
Where applicable, the difference between the scan versions has been clearly indicated in this documentation. Scan configurations and tokens are specific to a scan version: you cannot run Scan v2 engine using a Scan v1 scan token, and vice versa. You also cannot run a scan on a GraphQL API with a token for an OpenAPI scan configuration. When running a scan, make sure you specify the right scan token for the API and the scan version you are using, otherwise API Scan cannot use the associated scan configuration and fails to run.
You can run API Scan in 42Crunch Platform or on premises as a Docker image. GraphQL APIs and IDE integration are only supported in Scan v2.
| Feature | Scan v1 engine | Scan v2 engine |
|---|---|---|
| Mode of operation | ||
scand-agent (Docker image run on premises) |
✔ scand-agent v1.x.x available |
✔ scand-agent v2.x.x available |
scand-manager (Kubernetes service on run on premises) |
✔ scand-manager can run scand-agent v1.x.x |
✔ scand-manager can run scand-agent v2.x.x |
| Platform scan (scan run in42Crunch Platform) | ✔ Scan v1 can be run in 42Crunch Platform | ✔ Scan v2 can be run in 42Crunch Platform |
| Local executable (on-premise) | ❌ Not available | ✔ 42Crunch executable can run Scan v2 |
| Supported API types | ||
| OpenAPI definitions | ✔ Available | ✔ Available |
| GraphQL APIs | ❌ Not available | ✔ Available |
| Scan types | ||
| Conformance scan | ✔ Available | ✔ Available |
| Drift scan | ❌ Not available | ✔ Available (OpenAPI definitions only) |
| Tests in conformance scan for OpenAPI definitions | ||
| Schema injection tests v1 | ✔ Can run v1 schema injection tests | ✔ Can run v1 schema injection tests |
| Schema injection tests v2 | ❌ Not available | ✔ Can run v2 schema injection tests |
| Parameter injection tests v1 | ✔ Can run v1 parameter injection tests | ✔ Can run v1 parameter injection tests |
| Parameter injection tests v2 | ❌ Not available | ✔ Can run v2 parameter injection tests |
| Header injection tests v1 | ✔ Can run v1 header injection tests | ✔ Can run v1 header injection tests |
| Header injection tests v2 | ❌ Not available | ✔ Can run v2 header injection tests |
| Authentication tests | ❌ Not available | ✔ Can run authentication tests |
| Authorization tests | ❌ Not available | ✔ Can run authorization tests |
| HTTP method tests v1 | ✔ Can run v1 HTTP method tests | ✔ Can run v1 HTTP method tests |
| HTTP method tests v2 | ❌ Not available | ✔ Can run v2 HTTP method tests |
| Scenario playbook | ||
| Single happy path test | ✔ Can run single happy path test | ✔ Can run single happy path test |
| Advanced happy path test scenario | ❌ Not available | ✔ Can run happy path scenarios |
| Unhappy path scenarios | ❌ Not available | ✔ Supports unhappy path scenarios |
| Business test scenarios | ❌ Not available | ✔ Supports scan scenarios |
| Security test scenarios | ❌ Not available | ✔ Supports scan scenarios |
| Platform governance | ||
| Scan customization rules | ✔ Use customization rules from platform | ✔ Use customization rules from platform |
| Scan security quality gates | ✔ Scan report approval by SQG | ✔ Scan report approval by SQG |
| Additional features | ||
| Multiple scan configurations per API | ❌ Not available | ✔ Can create and edit multiple configurations for a single API |
| Lax testing mode | ❌ Not available | ✔ Run all tests even if happy path failed |
| Enhanced scan report navigation | ❌ Basic report | ✔ Enhanced scan report navigation available |
| IDE integration | ❌ Not available | ✔ Developers can run scan from IDE |
| Custom processing support | ❌ Not available | ✔ Custom processing of requests and responses through code plugins (JavaScript, Python, Golang) |
| Mutual TLS (mTLS) support | ✔ Available | ✔ Available |
To encourage migration away from the legacy Scan v1 engine to the Scan v2 engine, you can block running Scan v1 engine. For more details, see Block Scan v1 from regular users.
Testing undefined path items in OpenAPI definitions with Scan v2
Scan v2 engine provides more nuanced picture when testing methods (verbs) that have not been included as path items in the OpenAPI definition of your API.
With Scan v1 engine, when considering the baseline for the request to test undefined path items (path-item-method-not-allowed-scan), API Scan includes authentication into the baseline. If a path contains multiple operations with varying authentication requirements, scan chooses the authentication method at random.
For consistency and smooth transition, Scan v2 engine continues to execute this old style test, but it also implements a new test path-item-method-not-allowed-no-authn-scan with improved logic: instead of including authentication details into the baseline for the request, API Scan only modifies the method it calls for the path. This effectively separates authentication errors from unsupported methods so that the results better reflect what this particular test aims to achieve. If a path item requires authentication, Scan v2 engine relies on scan configuration to retrieve the correct authentication details.
What you can scan
- The file size of your API should not exceed 10 MB.
- The OpenAPI Specification (OAS) v2, v3.0, and v3.1 are supported. The API definition must be in JSON or YAML format (
.json,.yaml, or.yml).If you import OpenAPI definitions in YAML format to the platform, they are automatically converted and stored in JSON format. However, you can continue to view, edit, and download them in YAML format.
- GraphQL schema definition files (
.graphql,.graphqls,.gql,.gqls,.sdl) are supported. GraphQL introspection files are not supported. - GraphQL data definition files and supergraphs for GraphQL federation are supported.
Support for GraphQL is not enabled by default, but is available as a separate subscription.
By default, API Scan limits the maximum length for strings in the requests it sends during the scan to 4096. If the properties minLength or maxLength or the length limits in a regular expression that you have defined for an API operation in your API definition conflict with this limit, it causes issues during the scan.
If the minimum length required is longer than the string length limit allowed in API Scan, the scan cannot create the happy path request for that operation to establish a baseline. If the maximum length allowed in the API is longer than the allowed string length limit in API Scan, the scan can create the happy path request but not the actual request during the scan.
In both cases, the operation is shown as a skipped operation in the scan report, but for different reasons. You must fix the operation in your API definition before it can be successfully scanned.
API Scan does not support operations that require request bodies with the content type multipart/formData. Only request bodies with the content type application/json, application/x-www-form-urlencoded, or text/plain are supported.
If your API definition has regular expressions with either positive or negative lookaheads defined, these may cause weird behavior, for example, in API Scan.
Some scan settings, such as maximum size of the scan report, have an absolute maximum value that you cannot exceed. If you try, your scan might fail or you might not get a scan report. You can check what these values are on your 42Crunch Platform environment, see Check your platform URL
How API Scan works

- Preparation: API Scan checks the defined scan configuration and prepares the pieces required for the scan:
- Checks that the scan configuration you provided is valid.
- Parses the API definition of your API, generating default values for the parameters your API operations require.
- Checks that any certificates provided for authentication to the API endpoint are valid.
- Tests the designated endpoint to check that the server is available.
- Happy path tests: API Scan generates and sends a happy path test request to all operations in your API to establish a successful benchmark. By default, any operations where the happy path test fails are skipped in the scan.
- Generating tests: The scan generates the actual tests for the API operations in the scan based on the happy path requests.
- Scan:
API Scan sends the actual test requests at a constant flow rate to the live API endpoint.
- API Scan waits for the API to respond within 30 seconds before it raises a timeout error for the request in the scan logs.
- When the API responds, API Scan analyzes the received response to uncover issues and vulnerabilities.
Unlike the static testing in API Security Audit, API Scan is dynamic testing and variable by nature. To better simulate real API traffic and more reliably test the API's behavior, the requests and parameter values that API Scan generates are random. As a result, the API responses and the outcome of the scan can also vary. So do not be alarmed if you get slightly different results for your API in scans, that is completely normal.
If the response body in the response from the API exceeds 8 KB, it is truncated.
You can customize how API Scan behaves by creating scan rules and applying them to the APIs you want using tags. For more details, see Customizations.
Generating values for parameters
To successfully call the API operations in your API, API Scan must follow the API contract of the API and provide the required parameters in the calls. For this, when API Scan loads the API definition in memory, it generates default values for each schema and parameter in the API definition, and uses these values in the requests it sends. Because API Scan does not generate any responses itself (it only validates the responses coming directly from the API), response schemas are excluded.
For the intentionally malformed conformance test requests API Scan can simply generate random values, disregarding the constraints for schemas and parameters. However, for the happy path tests, the generated values must match all defined constraints.
Standard formats in OpenAPI definitions
Some formats are not random at all, but follow a standard pattern as defined in the OAS. API Scan uses a default generator to match the standard constraints of formats like:
- Date and time (uses the current date and time by default, formats as defined by RFC 3339)
- Email addresses
- Hostnames
- IP addresses (both IPv4 and IPv6)
- URIs
- JSON pointers
- UUIDs
If the data format itself does not set a standard pattern, API Scan uses the constraints set in your OpenAPI definition. If you provide a regular expression for a schema or parameter, API Scan uses that to generate the value. Otherwise, API Scan generates the value on its own.
Providing examples
It may be very difficult to create valid values for some things, like some object schemas, or strings with a very specific pattern. To ensure best performance, if you have complicated schemas in your API, we recommend including some examples for these kind of values directly in your API definition.
For OpenAPI definitions, there are several properties you can use for this, in the order of preference:
x-42c-sampledefaultenumexample(examplesin OAS v3.1)
If the property x-42c-sample contains a value that is not valid against the schema, API Scan tries to load the value from the property default, and so on, until it finds a sample value it can use. As a last resort, or if no samples are provided at all, API Scan generates a value from scratch. If API Scan cannot generate a default value that an API operation requires, that operation is skipped in the scan.
For GraphQL APIs, you can use the x-42c-sample in a comment block in your GraphQL API definition to provide examples that API Scan can use.
For more details on the vendor extension, see x-42c-sample. For more details on the other properties, see the OpenAPI Specification (OAS).
Conflicts from regular expressions in OpenAPI definitions
When generating values, API Scan considers the properties minLength, maxLength, and pattern separately. This means that if the string limitations in the regular expression in pattern do not match minLength and maxLength values API Scan may not be able to generate a valid value. To prevent this, if Security Audit detects a conflict between these string properties, it raises an issue about it that prevents scanning the API until the issue has been resolved.
There are several reasons why the conflict could happen. For example, instead of defining exact for length in the regular expression, you could have used + or *:
"example": {
"type": "string",
"minLength": 2,
"maxLength": 5,
"pattern": "^[a-z]+$"
}
We recommend that instead of using + or *, you properly specify the length in the regular expression. If the regular expression is simple, you can specify the length in both the pattern and minLength and maxLength, as long as the values do not conflict:
"example": {
"type": "string",
"minLength": 2,
"maxLength": 5,
"pattern": "^[a-z]{2,5}$"
}
If you have a complex regular expression with multiple segments, the lengths of all segments and minLength and maxLength must match. In this case, it is probably better to properly specify the length limits in the regular expression, and omit minLength and maxLength:
"example": {
"type": "string",
"pattern": "^(https?:\\/\\/)?(www\\.)?[-a-zA-Z0-9@:%._\\+~#=]{2,256}\\.[a-z]{2,6}\\b([-a-zA-Z0-9@:%_\\+.~#?&//=]*)$"
}
Remember to include the anchors ^ and $ in your regular expression, otherwise the overall length of the pattern could be considered infinite. If you include the anchors in the regular expression and the pattern only has fixed or constant quantifiers (like {10,64}, for example), you do not have to define the property maxLength separately for the object, as the length is fully constrained by the pattern. However, if the regular expression does not include the anchors or its quantifiers are not fixed (like in ^a.*b$), it can be considered to be just a part of a longer string and the property maxLength is required to constrain the length.
In both cases, it is always beneficial to provide an example value that API Scan can use when generating happy path requests.
Expected and unexpected HTTP status codes
HTTP status codes are a crucial part of API traffic: they allow communicating the status of a request back to its sender, like backend services responding back to clients and API consumers but also microservices communicating with other microservices within the same architecture. Especially in the latter case, sending back a wrong response code could have serious and unforeseen consequences down the line, which is why response code analysis is a critical part of API Scan.
The scan report for both OpenAPI and GraphQL APIs shows which HTTP status codes API Scan received as well as which it expected to receive for any given test. This helps you decide how to fix the possible issues. For Scan v1, API Scan also shows the source of its expectation for a particular HTTP code:
- 42Crunch default expectations: These are HTTP status codes that API Scan expects to receive based on standards, such as RFC 7231 or RFC 7235.
- Customization rules: These are HTTP status codes that have been defined as expected response codes in the scan rules applied to the scanned API.
We recommend using HTTP status codes as defined in RFCs as much as possible to avoid any accidental mismatches between the sending and the receiving end.
Types of tests
API Scan uses different types of tests for different purposes. Happy path test and conformance tests are part of both Scan v1 and Scan v2, but unhappy path tests and custom tests can only be configured for the new Scan v2, not for Scan v1.
Happy path tests
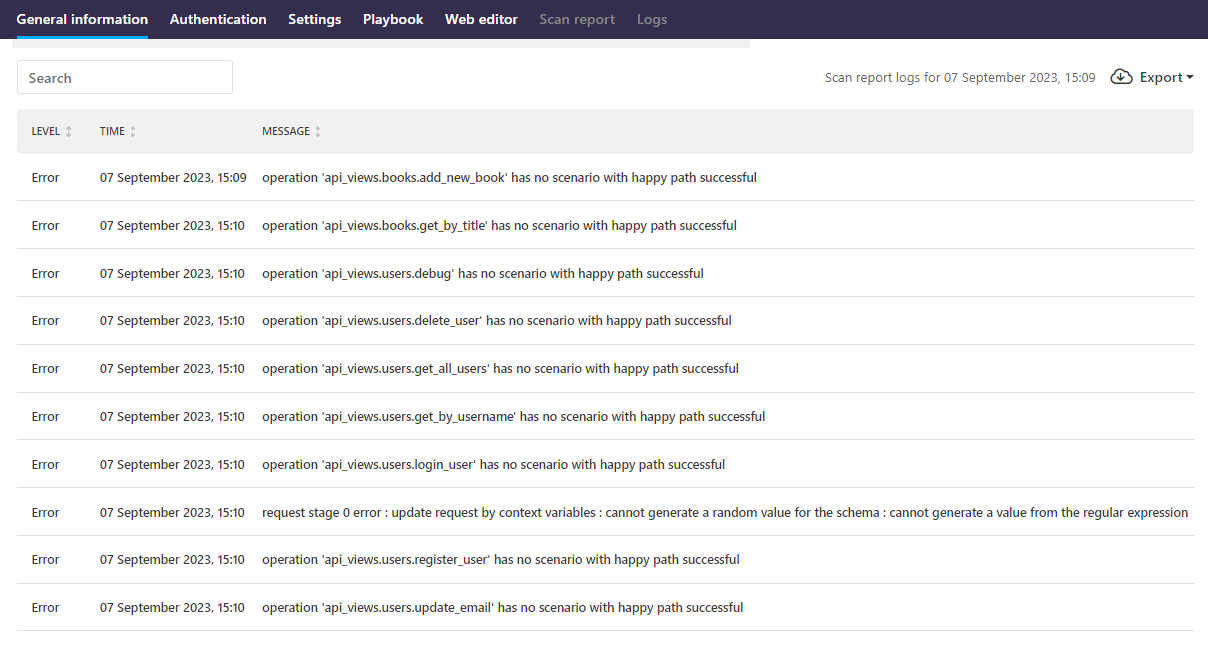
API Scan needs a benchmark to determine if the incorrect behavior of the API was caused by the test request or some other failure. To establish this benchmark, API Scan first runs a happy path test to the operations in the API before it starts the actual scan.
A happy path request is a valid request generated directly from the API definition of your API, designed and expected to always succeed. To run happy path tests API Scan generates and sends this request to each operation defined in your API, and validates the responses it received.
For a happy path test to be a success, the received response from the API must be either successful or expected:
- For OpenAPI definitions, the received HTTP status code must be
200—399, or404(because the likelihood that the scan manages to generate a value that matches an existing ID is vanishingly small). - For GraphQL APIs, the received HTTP status code must be
200.
Otherwise, the happy path test fails. If a happy path test fails, the operation in question is skipped in the scan, because any results for it would be inconclusive without a successful benchmark.
A failing happy path test often indicates significant issues in your API definition that you must fix before API Scan can scan the failing operation. Running Security Audit and checking what kind of issues it raises helps you find the culprits. The happy path test can also fail because the connection to the defined endpoint was broken, or the API took too long (over 30 seconds) to respond.
If any of the happy path tests fail during the scan, the scan is marked as incomplete. If all API operations cannot be scanned, it is impossible to know what sort of issues API Scan might uncover on the untested ones and thus the achieved results cannot be considered as the full story. Only once all happy path tests are passing and all operations in the API can be scanned can the scan be considered complete.
If your API defines more than one HTTP status code for success and you want to test all of these, you can define additional scan scenarios to ensure happy path tests cover all response codes.
Lax testing mode
This applies to Scan v2 engine only.
In the normal testing mode, any operations where the happy path test fails are skipped in the scan, because API Scan could not establish a baseline against which to compare the scan results. However, sometimes it might be useful to scan operations regardless of failing happy path tests, even if the scan results might not be as reliable.
For this purpose, you can change the setting for the scan testing mode from the normal mode to lax testing mode in the scan configuration of your API. In lax testing mode, API Scan still runs happy path tests and notes if they succeeded or failed, but it also runs the actual tests even on operations with failed happy path tests. You can see in the scan report which testing mode was used.
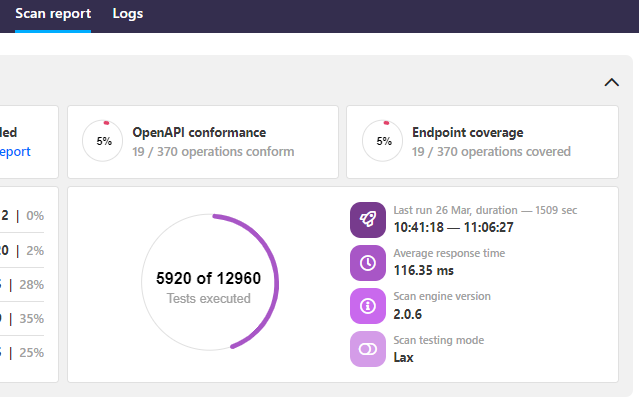
Depending on your API and the scan configuration, changing the normal testing mode to lax may result in significantly more tests and bigger scan reports than before, so you may have to adjust your scan settings to get the full scan report.
Lax scan testing mode is only supported in the Scan v2 Docker image v2.0.6 or higher.
Unhappy path tests
This applies to Scan v2 engine only.
Happy path tests, as their name implies, are the cases where everything goes well, which in most cases is how things should go. But sometimes you might want to test the implementation for HTTP response status codes for errors (usually 4XX). Because the happy path tests consider these response codes as unsuccessful, they cannot provide the baseline for how the received response for error codes should look like. This is where unhappy path tests come into play.
To be able to see how the API responses from your error handling do in API Scan, you can configure unhappy path tests that define what to normally expect for the specific error responses you want to test. API Scan will run the unhappy path tests alongside the normal happy path tests to establish the baseline for the normal API responses from error handling, so that it can run the actual test requests against these endpoints during the scan.
Unhappy path tests are configured as scan scenarios.
Actual tests
Once API Scan has the baseline for what a success for a particular API operation looks like, it is ready to test the API implementation in action. These actual test requests that API Scan runs are specifically designed to uncover inconsistencies, vulnerabilities or other issues in your API implementation, depending on the type of the scan.
Custom tests
This applies to Scan v2 engine only.
Sometimes you might want to test a very specific thing in your API implementation and the normal tests cannot catch that. In this case, you can write your own custom test that captures the issue you want to test. The custom test can be as complex or as simple as needed: for example, you might just want to check that an authorization scenario works with the correct credentials, or you might want to define a test that would inject a specific input to see how your API behaves.
Custom tests are configured as scan scenarios for a particular operation. You cannot define a custom test on a global level for your whole API.
Types of scans
You can use API Scan to run different types of scans that focus on different aspects of your API implementation. In all scans, the underlying scan engine is the same, but the scan configuration that the engine uses includes different instructions on what kind of requests to generate for the scan.
Different scan types are only available only when using Scan v2 engine. Scan v1 engine can only run conformance scan.
API Scan can run the following types of scans:
- Conformance scan: A design-time scan to ensure that you do not inadvertently introduce vulnerabilities and your code and API implementation matches the documented contract in your API definition. Both OpenAPI definitions and GraphQL APIs are supported.
- Drift scan: A lightweight scan on deployed and operational APIs to ensure they continue to work the expected way. Currently, only OpenAPI definitions are supported.
For more details on the different scan types, see Types of scans in API Scan.
Scan configuration
To successfully scan an API, API Scan needs some basic information on what it is supposed to do:
- What API to scan?
- Which endpoint to send the requests to?
- How to authenticate to the API, if that is required?
- What kind of tests and what type of scan to run?
For this, API Scan needs a scan configuration, a JSON file that captures these details for each API that you want to scan.
You can quickly create a basic scan configuration in 42Crunch Platform by providing some basic information, or if a more complex scan configuration is needed, you may choose to work on it outside the platform in an editor of your choice and upload the finished configuration to the platform. You can also update your existing configurations later, for example, to enhance them or take advantage of new improvements. Scan configurations are stored encrypted in 42Crunch Platform. Regular users can only create scan configurations and run scan on APIs they have at least read/write access to. Organization administrators can create scan configurations and scan all APIs in their organization.
All available scan configurations for an API are listed on the API Scan page. How many scan configurations a single API can have depends on the version of the scan you want:
- For Scan v1 engine, you can have one scan configuration for running API Scan in 42Crunch Platform and another for running it on premises. You can update these configurations as needed, but you cannot create more scan configurations. Because the underlying scan configuration is the same, both Scan v1 configurations are shown together on the UI.
- For Scan v2 engine, you can have as many scan configurations as needed and edit them freely. All Scan v2 configurations can be run either in 42Crunch Platform or on premises. When run in the platform, some settings are capped to a lower level than what is allowed in on-premises scans.
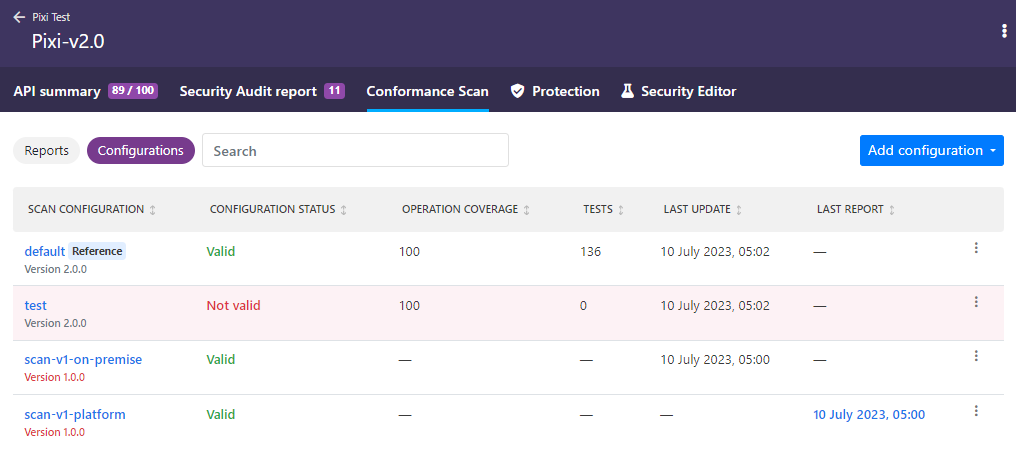
You can see where configurations were last run and with which scan image version, and you have the link to the latest scan report stored in 42Crunch Platform. For Scan v2 configurations, you can also see what percentage of the API operations in the API they cover. If you click on a configuration, you can view more details about it, such as its settings.
If your API changes, its scan configurations are not automatically updated, instead they are marked with as being outdated. Depending on the changes in the API, a scan configuration might still continue to be valid, and you can continue to use it in a scan. For example, a fixed typo in a description does not functionally change anything, but if you changed how an API operation works, or added a new API operation, an existing scan configuration could not take these into account when running a scan. Therefore, you should check that the scan configuration continues to work for your API after the changes.
To include the changes in the scan configuration, you must create a new configuration. This is the fastest way to ensure that the scenarios for your API operations match your API contract. You can then copy the change you need from the new configuration and paste it into your existing ones, continuing to edit them as needed.
For more information on what you can do with scan configurations, see Scan configuration details.
Reference scan configuration
Reference scan configuration is the quality reference for your API: because a single API can have multiple scan configurations for different purposes (like testing in general or very specific scenarios), not all of them give as good a picture of the overall quality of your API.
For example, a configuration for testing a specific scenario might only need to cover a few of your APIs endpoints, so the results would not properly describe your API as a whole. Or you might have just started to experiment with Scan v2 engine and so your scan configuration for that might still be a work in progress. For this reason, it is possible to choose which of the scan configurations best represents how good the API implementation is overall.
The statistics and results of the reference scan configuration are the ones shown for your API in the list of APIs in the API collection, and on the scan results, scan trends, and the security quality gate (SQG) status that are displayed on the API summary tab. You can view the results from other configurations in the list of scan reports, but only the results from your reference scan configuration are shown elsewhere.
It usually makes sense to first try a scan configuration to see how the results look before choosing it as the reference configuration. If you set a scan configuration as the reference configuration before running API Scan using it, your API will not show any scan results (except in the report list) even if you had scanned the API using other scan configurations. Of course, if your API only has one scan configuration, then that also automatically is the reference configuration.
Because the reference scan configuration is needed to provide scan statistics for your API, you cannot delete that scan configuration before you choose a new reference scan configuration.
Scan token
Creating a scan configuration also produces a scan token. The token indicates to API Scan which API it should scan and with which settings. If running API Scan on premises in a Docker container, the scan token is passed in the environment variable SCAN_TOKEN. When API Scan starts, it connects to 42Crunch Platform and fetches the scan configuration that matches the specified scan token. This ensures that the on-premise scan runs the correct configuration for your API. If running API Scan in 42Crunch Platform, you do not have to provide the scan token separately.
Scan configurations and tokens are specific to a scan version: you cannot run Scan v2 engine using a Scan v1 scan token, and vice versa. You also cannot run a scan on a GraphQL API with a token for an OpenAPI scan configuration. When running a scan, make sure you specify the right scan token for the API and the scan version you are using, otherwise API Scan cannot use the associated scan configuration and fails to run.
When the on-premises scan starts, it establishes a two-way, HTTP/2 gRPC connection to 42Crunch Platform at the address services.<your hostname> and the port 8001. Make sure that your network configuration (like your network firewall) authorizes these connections. The on-premises scan uses this connection to verify the scan token and to download the scan configuration you have created. During runtime, on-premises scan uses the connection to send the scan report and logs to the platform.
If you are an enterprise customer not accessing 42Crunch Platform at https://us.42crunch.cloud, your hostname is the same one as in your platform URL.
Scan configuration validation report (SCVR)
This applies to Scan v2 engine only.
Currently, GraphQL APIs are not supported.
Whenever you create, update, or upload a scan configuration for an OpenAPI definition, API Scan checks the created configuration and provides a scan configuration validation report (SCVR) that gives you useful information on the configuration, such as:
- How many API endpoints and response HTTP status codes defined for the API in question does the scan configuration cover.
- How many tests API Scan can run using this configuration.
- How many custom tests have been defined in the scan configuration.
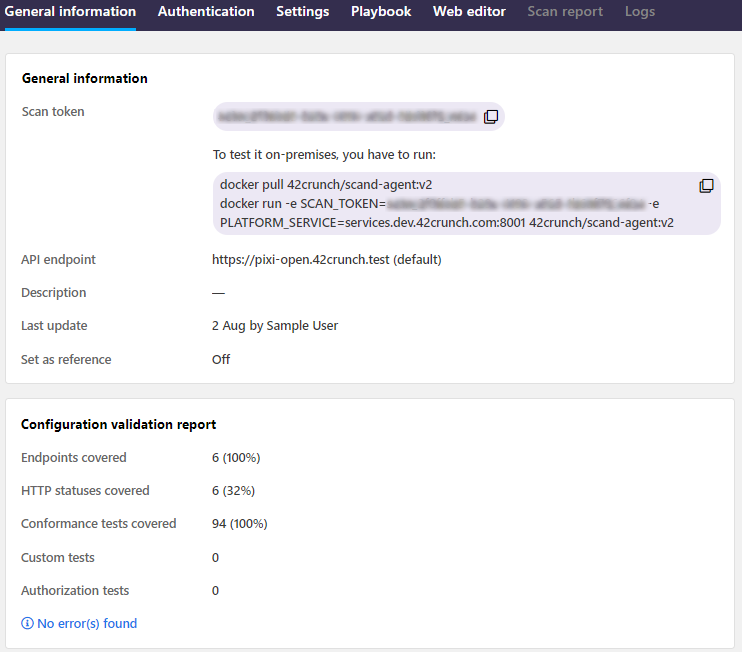
By default, the basic scan configuration that 42Crunch Platform creates automatically is based directly on the OpenAPI definition of the API, and thus always valid for that API. However, if you edit the basic configuration further, or indeed create a more complex scan configuration with additional features, it is possible that you might inadvertently introduce discrepancies or errors into the scan configuration so that API Scan could no longer successfully scan the API because the scan configuration now contradicts its API definition.
The SCVR lets you detect such errors already before you run API Scan: if API Scan finds any discrepancies that would automatically mean that the scan could not successfully run with that configuration, these errors are flagged to you in the SCVR so that you can fix them.
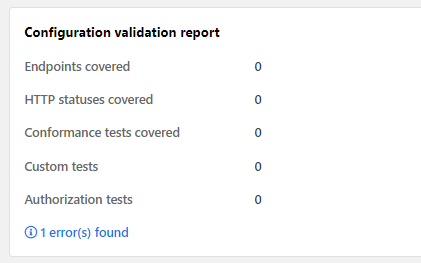
You cannot run a scan using a scan configuration that is not valid for the API definition in question. You also do not get coverage statistics until the configuration has been fixed.
Scan report
API Scan produces a scan report that provides valuable information on the issues and vulnerabilities that the scan found in your API implementation. Each scan configuration that you have used to run a scan shows the report from the latest scan that summarizes how the scan went and how severe the found problems are.
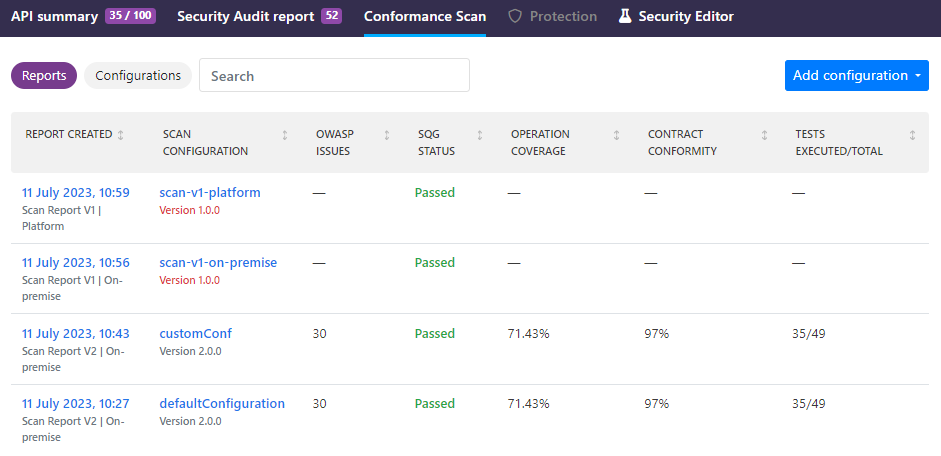
The contents of the report and what kind of issues are reported depends on the type of scan. For more details on the reports from different types of scans, see Types of scans in API Scan.
You can download a copy of the report, for example, to share the results outside the platform. If you do not want the full report with all the details, you can also export just the found issues as a CSV list.
Running API Scan on premises
Running API Scan in 42Crunch Platform is quick and straightforward, but in some cases it might not offer enough options for your needs, or you might want to store the data from scans in your own system. In this case, you can deploy and run API Scan locally as a Docker image.
To run on-premises scan, you create a scan configuration in 42Crunch Platform and then pull and run the API Scan Docker image from Docker Hub, using the configuration you created by providing the scan token of the configuration to be used in your Docker command. Scan configurations and tokens are specific to a scan version: you cannot run Scan v2 engine using a Scan v1 scan token, and vice versa. You also cannot run a scan on a GraphQL API with a token for an OpenAPI scan configuration. When running a scan, make sure you specify the right scan token for the API and the scan version you are using, otherwise API Scan cannot use the associated scan configuration and fails to run. You must update your scan configuration before you can see the effect from some updates to API Scan.
When the on-premises scan starts, it establishes a two-way, HTTP/2 gRPC connection to 42Crunch Platform at the address services.<your hostname> and the port 8001. Make sure that your network configuration (like your network firewall) authorizes these connections. The on-premises scan uses this connection to verify the scan token and to download the scan configuration you have created. During runtime, on-premises scan uses the connection to send the scan report and logs to the platform.
If you are an enterprise customer not accessing 42Crunch Platform at https://us.42crunch.cloud, your hostname is the same one as in your platform URL.
You can check where (in 42Crunch Platform or on premises) the latest scan was run on the API summary page.
If you are on the API summary page or in the list of scan reports on the UI when the scan finishes, you must refresh the page before the on-premises scan report is available on the UI.
For more details on how to run the on-premises scan and customize the scan configuration, see Scan APIs.
Using environment variables with Scan v1 engine
When running API Scan on premises, you can use environment variables and supply values for them in your Docker command when you run the scan. This way you can easily test the different authentication methods in your OpenAPI definition.
When configuring the authentication for on-premises scan configuration, you can enter an environment variable to any field instead of hard-coding a value. The environment variable can be called anything you want, as long as fulfills the following criteria:
- Must be inside curly brackets (
{}) - Must start with
$ - Cannot contain other special characters than
-,_, and. - Must be longer than one character (just
{$}is not a valid environment variable)
Environment variables are currently not supported for mutual TLS password.
When you run the on-premises scan, you provide the values for the environment variables in your run command. The variables must have SECURITY_ added before them, for example:
docker run -e SCAN_TOKEN=<your scan token> -e SECURITY_ACCESS_TOKEN='<the access token value you want to use>' 42crunch/scand-agent:latest
Providing authentication details for Scan v2 engine
With Scan v2 engine, the scan configuration is generated automatically from the API definition of the API. For OpenAPI definitions, this includes the authentication details, because they are described as part of the API definition itself. All authentication methods found in the OpenAPI definition are automatically given the environment variables (for example, SCAN42C_SECURITY_ACCESS_TOKEN) that can be used to provide the values for credentials in the Docker command when running the scan.
docker run -e SCAN_TOKEN=<your scan token> -e PLATFORM_SERVICE=services.us.42crunch.cloud:8001 -e SCAN42C_SECURITY_ACCESS_TOKEN='<the token value you want to use>' 42crunch/scand-agent:v2
For Scan v2 engine, if you do not provide credentials to all authentication methods listed as required in your scan configuration, API Scan cannot run tests on all API operations because it cannot authenticate to your API. If you have defined an authentication method in your OpenAPI definition but your API does not actually use it, you can mark it in your scan configuration as not required at runtime to avoid having to provide credentials for it.
For GraphQL APIs, authentication information is not included in the scan configuration by default, because it is completely external to the API definition and cannot be inferred from it. If API consumers — and therefore also API Scan — must authenticate to your API, after creating the scan configuration you must edit it to include the required authentication details. You can either include the credential value in the configuration, or you can use environment variables. If using a variable (called, for example, ENV_VAR in your configuration), you add flags in the Docker command just like when scanning an OpenAPI file:
docker run -e SCAN_TOKEN=<your scan token> -e PLATFORM_SERVICE=services.us.42crunch.cloud:8001 -e SCAN42C_ENV_VAR='<the variable value you want to use>' 42crunch/scand-agent:v2
If you did not use a variable when configuring the authentication, you do not need to provide credentials in your Docker command.
Scan logs
As part of its operation API Scan produces logs. By default, the logs are stored and can be viewed in the platform, but when running API Scan (either Scan v1 or Scan v2 engine) on premises, there are more options.
By default, API Scan run on premises writes all log levels as standard output (STDOUT) to console and your terminal, but only uploads error and critical level scan logs to 42Crunch Platform. You can also direct the STDOUT logs to be consumed downstream services (see the documentation for your environment for how this is done), or write the logs in a volume that you mount as part of your run command. The scan writes logs to the file <your local filepath>/opt/scand/log/<task ID>-<epoch timestamp>-scand.log.
The default size limit for the log file is 100 MB, but you can also limit the size more, if needed. When you create the scan configuration for on-premises scan, you can also choose how many issues you want the scan to report (default is 1000). Decreasing the maximum number of reported issues also decreases the maximum possible size of a single scan report. Large response bodies do not inflate the logs: response bodies over 8 KB are truncated.
If the log file size exceeds the size of the volume you mounted, the scan raises errors but API Scan continues to run normally. These errors are also uploaded to 42Crunch Platform, but the rest of the debug and info level logs are only written as STDOUT, not to file.
If you set the log level to debug when running Scan v2, all the values of all variables in your scan configuration are printed in the clear in the scan logs. Depending on your API, this can include credentials.
Errors in API Scan
Occasionally, API Scan might fail to scan your API. The reason for this could be, for example:
- Invalid API definition: You API definition has critical errors that are preventing API Scan from running. For example, the structure of your API might not conform to the standard it claims to follow. Use API Security Audit to check your API definition and fix any found issues in Security Editor, then try API Scan again.
- Invalid scan configuration: The configuration you set up for the scan does not match your API definition and thus is not valid. For example, you might have chosen an authentication method that does not match the ones defined in your API definition. Try configuring and running API Scan again, making sure the authentication details match your API definition.
- Scan cannot reach API endpoint: API Scan tried to run the scan but failed to reach the API endpoint you had selected for the scan. The API host could be down, or there could be an error in the URL, especially if entered a custom URL. Check the URL and the host of your API and try again.
- Timeout: The scan took longer than the maximum scan duration (3600 seconds).